Chapter 9. Finding and fixing mistakes
Table of Contents
To err might be human, but to really handle the consequences well takes a top-notch revision control system. In this chapter, we'll discuss some of the techniques you can use when you find that a problem has crept into your project. Mercurial has some highly capable features that will help you to isolate the sources of problems, and to handle them appropriately.
Erasing local history
The accidental commit
I have the occasional but persistent problem of typing rather more quickly than I can think, which sometimes results in me committing a changeset that is either incomplete or plain wrong. In my case, the usual kind of incomplete changeset is one in which I've created a new source file, but forgotten to hg add it. A “plain wrong” changeset is not as common, but no less annoying.
Rolling back a transaction
In the section called “Safe operation”, I mentioned that Mercurial treats each modification of a repository as a transaction. Every time you commit a changeset or pull changes from another repository, Mercurial remembers what you did. You can undo, or roll back, exactly one of these actions using the hg rollback command. (See the section called “Rolling back is useless once you've pushed” for an important caveat about the use of this command.)
Here's a mistake that I often find myself making: committing a change in which I've created a new file, but forgotten to hg add it.
$hg statusM a$echo b > b$hg commit -m 'Add file b'
Looking at the output of hg status after the commit immediately confirms the error.
$hg status? b$hg tipchangeset: 1:f2db1de2ba4f tag: tip user: Bryan O'Sullivan <[email protected]> date: Tue May 05 06:55:44 2009 +0000 summary: Add file b
The commit captured the changes to the file
a, but not the new file
b. If I were to push this changeset to a
repository that I shared with a colleague, the chances are
high that something in a would refer to
b, which would not be present in their
repository when they pulled my changes. I would thus become
the object of some indignation.
However, luck is with me—I've caught my error before I pushed the changeset. I use the hg rollback command, and Mercurial makes that last changeset vanish.
$hg rollbackrolling back last transaction$hg tipchangeset: 0:cde70bc943e1 tag: tip user: Bryan O'Sullivan <[email protected]> date: Tue May 05 06:55:44 2009 +0000 summary: First commit$hg statusM a ? b
Notice that the changeset is no longer present in the
repository's history, and the working directory once again
thinks that the file a is modified. The
commit and rollback have left the working directory exactly as
it was prior to the commit; the changeset has been completely
erased. I can now safely hg
add the file b, and rerun my
commit.
$hg add b$hg commit -m 'Add file b, this time for real'
The erroneous pull
It's common practice with Mercurial to maintain separate development branches of a project in different repositories. Your development team might have one shared repository for your project's “0.9” release, and another, containing different changes, for the “1.0” release.
Given this, you can imagine that the consequences could be messy if you had a local “0.9” repository, and accidentally pulled changes from the shared “1.0” repository into it. At worst, you could be paying insufficient attention, and push those changes into the shared “0.9” tree, confusing your entire team (but don't worry, we'll return to this horror scenario later). However, it's more likely that you'll notice immediately, because Mercurial will display the URL it's pulling from, or you will see it pull a suspiciously large number of changes into the repository.
The hg rollback command will work nicely to expunge all of the changesets that you just pulled. Mercurial groups all changes from one hg pull into a single transaction, so one hg rollback is all you need to undo this mistake.
Rolling back is useless once you've pushed
The value of the hg rollback command drops to zero once you've pushed your changes to another repository. Rolling back a change makes it disappear entirely, but only in the repository in which you perform the hg rollback. Because a rollback eliminates history, there's no way for the disappearance of a change to propagate between repositories.
If you've pushed a change to another repository—particularly if it's a shared repository—it has essentially “escaped into the wild,” and you'll have to recover from your mistake in a different way. If you push a changeset somewhere, then roll it back, then pull from the repository you pushed to, the changeset you thought you'd gotten rid of will simply reappear in your repository.
(If you absolutely know for sure that the change you want to roll back is the most recent change in the repository that you pushed to, and you know that nobody else could have pulled it from that repository, you can roll back the changeset there, too, but you really should not expect this to work reliably. Sooner or later a change really will make it into a repository that you don't directly control (or have forgotten about), and come back to bite you.)
You can only roll back once
Mercurial stores exactly one transaction in its transaction log; that transaction is the most recent one that occurred in the repository. This means that you can only roll back one transaction. If you expect to be able to roll back one transaction, then its predecessor, this is not the behavior you will get.
$hg rollbackrolling back last transaction$hg rollbackno rollback information available
Once you've rolled back one transaction in a repository, you can't roll back again in that repository until you perform another commit or pull.
Reverting the mistaken change
If you make a modification to a file, and decide that you really didn't want to change the file at all, and you haven't yet committed your changes, the hg revert command is the one you'll need. It looks at the changeset that's the parent of the working directory, and restores the contents of the file to their state as of that changeset. (That's a long-winded way of saying that, in the normal case, it undoes your modifications.)
Let's illustrate how the hg revert command works with yet another small example. We'll begin by modifying a file that Mercurial is already tracking.
$cat fileoriginal content$echo unwanted change >> file$hg diff filediff -r b52afd4afc59 file --- a/file Tue May 05 06:55:32 2009 +0000 +++ b/file Tue May 05 06:55:32 2009 +0000 @@ -1,1 +1,2 @@ original content +unwanted change
If we don't want that change, we can simply hg revert the file.
$hg statusM file$hg revert file$cat fileoriginal content
The hg revert command
provides us with an extra degree of safety by saving our
modified file with a .orig
extension.
$hg status? file.orig$cat file.origoriginal content unwanted change
![[Tip]](figs/tip.png)
Here is a summary of the cases that the hg revert command can deal with. We will describe each of these in more detail in the section that follows.
If you modify a file, it will restore the file to its unmodified state.
If you hg add a file, it will undo the “added” state of the file, but leave the file itself untouched.
If you delete a file without telling Mercurial, it will restore the file to its unmodified contents.
If you use the hg remove command to remove a file, it will undo the “removed” state of the file, and restore the file to its unmodified contents.
File management errors
The hg revert command is useful for more than just modified files. It lets you reverse the results of all of Mercurial's file management commands—hg add, hg remove, and so on.
If you hg add a file, then decide that in fact you don't want Mercurial to track it, use hg revert to undo the add. Don't worry; Mercurial will not modify the file in any way. It will just “unmark” the file.
$echo oops > oops$hg add oops$hg status oopsA oops$hg revert oops$hg status? oops
Similarly, if you ask Mercurial to hg remove a file, you can use hg revert to restore it to the contents it had as of the parent of the working directory.
$hg remove file$hg statusR file$hg revert file$hg status$ls filefile
This works just as well for a file that you deleted by hand, without telling Mercurial (recall that in Mercurial terminology, this kind of file is called “missing”).
$rm file$hg status! file$hg revert file$ls filefile
If you revert a hg copy, the copied-to file remains in your working directory afterwards, untracked. Since a copy doesn't affect the copied-from file in any way, Mercurial doesn't do anything with the copied-from file.
$hg copy file new-file$hg revert new-file$hg status? new-file
Dealing with committed changes
Consider a case where you have committed a change a, and another change b on top of it; you then realise that change a was incorrect. Mercurial lets you “back out” an entire changeset automatically, and building blocks that let you reverse part of a changeset by hand.
Before you read this section, here's something to keep in mind: the hg backout command undoes the effect of a change by adding to your repository's history, not by modifying or erasing it. It's the right tool to use if you're fixing bugs, but not if you're trying to undo some change that has catastrophic consequences. To deal with those, see the section called “Changes that should never have been”.
Backing out a changeset
The hg backout command lets you “undo” the effects of an entire changeset in an automated fashion. Because Mercurial's history is immutable, this command does not get rid of the changeset you want to undo. Instead, it creates a new changeset that reverses the effect of the to-be-undone changeset.
The operation of the hg backout command is a little intricate, so let's illustrate it with some examples. First, we'll create a repository with some simple changes.
$hg init myrepo$cd myrepo$echo first change >> myfile$hg add myfile$hg commit -m 'first change'$echo second change >> myfile$hg commit -m 'second change'
The hg backout command
takes a single changeset ID as its argument; this is the
changeset to back out. Normally, hg
backout will drop you into a text editor to write
a commit message, so you can record why you're backing the
change out. In this example, we provide a commit message on
the command line using the -m option.
Backing out the tip changeset
We're going to start by backing out the last changeset we committed.
$hg backout -m 'back out second change' tipreverting myfile changeset 2:01adc4672142 backs out changeset 1:7e341ee3be7a$cat myfilefirst change
You can see that the second line from
myfile is no longer present. Taking a
look at the output of hg log
gives us an idea of what the hg
backout command has done.
$hg log --style compact2[tip] 01adc4672142 2009-05-05 06:55 +0000 bos back out second change 1 7e341ee3be7a 2009-05-05 06:55 +0000 bos second change 0 56b97fc928f2 2009-05-05 06:55 +0000 bos first change
Notice that the new changeset that hg backout has created is a child of the changeset we backed out. It's easier to see this in Figure 9.1, “Backing out a change using the hg backout command”, which presents a graphical view of the change history. As you can see, the history is nice and linear.
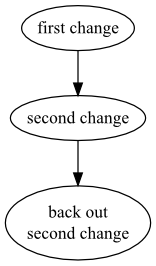
Backing out a non-tip change
If you want to back out a change other than the last one
you committed, pass the --merge option to the
hg backout command.
$cd ..$hg clone -r1 myrepo non-tip-reporequesting all changes adding changesets adding manifests adding file changes added 2 changesets with 2 changes to 1 files updating working directory 1 files updated, 0 files merged, 0 files removed, 0 files unresolved$cd non-tip-repo
This makes backing out any changeset a “one-shot” operation that's usually simple and fast.
$echo third change >> myfile$hg commit -m 'third change'$hg backout --merge -m 'back out second change' 1reverting myfile created new head changeset 3:abc7fd860049 backs out changeset 1:7e341ee3be7a merging with changeset 3:abc7fd860049 merging myfile 0 files updated, 1 files merged, 0 files removed, 0 files unresolved (branch merge, don't forget to commit)
If you take a look at the contents of
myfile after the backout finishes, you'll
see that the first and third changes are present, but not the
second.
$cat myfilefirst change third change
As the graphical history in Figure 9.2, “Automated backout of a non-tip change using the hg backout command” illustrates, Mercurial still commits one change in this kind of situation (the box-shaped node is the ones that Mercurial commits automatically), but the revision graph now looks different. Before Mercurial begins the backout process, it first remembers what the current parent of the working directory is. It then backs out the target changeset, and commits that as a changeset. Finally, it merges back to the previous parent of the working directory, but notice that it does not commit the result of the merge. The repository now contains two heads, and the working directory is in a merge state.

The result is that you end up “back where you were”, only with some extra history that undoes the effect of the changeset you wanted to back out.
You might wonder why Mercurial does not commit the result of the merge that it performed. The reason lies in Mercurial behaving conservatively: a merge naturally has more scope for error than simply undoing the effect of the tip changeset, so your work will be safest if you first inspect (and test!) the result of the merge, then commit it.
Gaining more control of the backout process
While I've recommended that you always use the --merge option when backing
out a change, the hg backout
command lets you decide how to merge a backout changeset.
Taking control of the backout process by hand is something you
will rarely need to do, but it can be useful to understand
what the hg backout command
is doing for you automatically. To illustrate this, let's
clone our first repository, but omit the backout change that
it contains.
$cd ..$hg clone -r1 myrepo newreporequesting all changes adding changesets adding manifests adding file changes added 2 changesets with 2 changes to 1 files updating working directory 1 files updated, 0 files merged, 0 files removed, 0 files unresolved$cd newrepo
As with our earlier example, We'll commit a third changeset, then back out its parent, and see what happens.
$echo third change >> myfile$hg commit -m 'third change'$hg backout -m 'back out second change' 1reverting myfile created new head changeset 3:abc7fd860049 backs out changeset 1:7e341ee3be7a the backout changeset is a new head - do not forget to merge (use "backout --merge" if you want to auto-merge)
Our new changeset is again a descendant of the changeset we backout out; it's thus a new head, not a descendant of the changeset that was the tip. The hg backout command was quite explicit in telling us this.
$hg log --style compact3[tip]:1 abc7fd860049 2009-05-05 06:55 +0000 bos back out second change 2 bae4005ddac4 2009-05-05 06:55 +0000 bos third change 1 7e341ee3be7a 2009-05-05 06:55 +0000 bos second change 0 56b97fc928f2 2009-05-05 06:55 +0000 bos first change
Again, it's easier to see what has happened by looking at a graph of the revision history, in Figure 9.3, “Backing out a change using the hg backout command”. This makes it clear that when we use hg backout to back out a change other than the tip, Mercurial adds a new head to the repository (the change it committed is box-shaped).
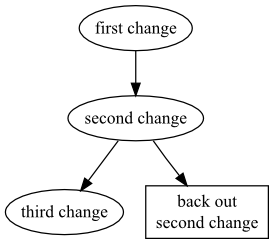
After the hg backout command has completed, it leaves the new “backout” changeset as the parent of the working directory.
$hg parentschangeset: 2:bae4005ddac4 user: Bryan O'Sullivan <[email protected]> date: Tue May 05 06:55:12 2009 +0000 summary: third change
Now we have two isolated sets of changes.
$hg headschangeset: 3:abc7fd860049 tag: tip parent: 1:7e341ee3be7a user: Bryan O'Sullivan <[email protected]> date: Tue May 05 06:55:12 2009 +0000 summary: back out second change changeset: 2:bae4005ddac4 user: Bryan O'Sullivan <[email protected]> date: Tue May 05 06:55:12 2009 +0000 summary: third change
Let's think about what we expect to see as the contents of
myfile now. The first change should be
present, because we've never backed it out. The second change
should be missing, as that's the change we backed out. Since
the history graph shows the third change as a separate head,
we don't expect to see the third change
present in myfile.
$cat myfilefirst change
To get the third change back into the file, we just do a normal merge of our two heads.
$hg mergeabort: outstanding uncommitted changes$hg commit -m 'merged backout with previous tip'$cat myfilefirst change
Afterwards, the graphical history of our repository looks like Figure 9.4, “Manually merging a backout change”.
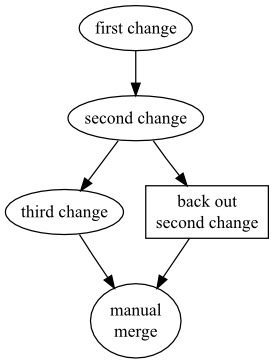
Why hg backout works as it does
Here's a brief description of how the hg backout command works.
It ensures that the working directory is “clean”, i.e. that the output of hg status would be empty.
It remembers the current parent of the working directory. Let's call this changeset
orig.It does the equivalent of a hg update to sync the working directory to the changeset you want to back out. Let's call this changeset
backout.It finds the parent of that changeset. Let's call that changeset
parent.For each file that the
backoutchangeset affected, it does the equivalent of a hg revert -r parent on that file, to restore it to the contents it had before that changeset was committed.It commits the result as a new changeset. This changeset has
backoutas its parent.If you specify
--mergeon the command line, it merges withorig, and commits the result of the merge.
An alternative way to implement the hg backout command would be to
hg export the
to-be-backed-out changeset as a diff, then use the --reverse option to the
patch command to reverse the effect of the
change without fiddling with the working directory. This
sounds much simpler, but it would not work nearly as
well.
The reason that hg backout does an update, a commit, a merge, and another commit is to give the merge machinery the best chance to do a good job when dealing with all the changes between the change you're backing out and the current tip.
If you're backing out a changeset that's 100 revisions back in your project's history, the chances that the patch command will be able to apply a reverse diff cleanly are not good, because intervening changes are likely to have “broken the context” that patch uses to determine whether it can apply a patch (if this sounds like gibberish, see the section called “Understanding patches” for a discussion of the patch command). Also, Mercurial's merge machinery will handle files and directories being renamed, permission changes, and modifications to binary files, none of which patch can deal with.
Changes that should never have been
Most of the time, the hg backout command is exactly what you need if you want to undo the effects of a change. It leaves a permanent record of exactly what you did, both when committing the original changeset and when you cleaned up after it.
On rare occasions, though, you may find that you've committed a change that really should not be present in the repository at all. For example, it would be very unusual, and usually considered a mistake, to commit a software project's object files as well as its source files. Object files have almost no intrinsic value, and they're big, so they increase the size of the repository and the amount of time it takes to clone or pull changes.
Before I discuss the options that you have if you commit a “brown paper bag” change (the kind that's so bad that you want to pull a brown paper bag over your head), let me first discuss some approaches that probably won't work.
Since Mercurial treats history as accumulative—every change builds on top of all changes that preceded it—you generally can't just make disastrous changes disappear. The one exception is when you've just committed a change, and it hasn't been pushed or pulled into another repository. That's when you can safely use the hg rollback command, as I detailed in the section called “Rolling back a transaction”.
After you've pushed a bad change to another repository, you could still use hg rollback to make your local copy of the change disappear, but it won't have the consequences you want. The change will still be present in the remote repository, so it will reappear in your local repository the next time you pull.
If a situation like this arises, and you know which repositories your bad change has propagated into, you can try to get rid of the change from every one of those repositories. This is, of course, not a satisfactory solution: if you miss even a single repository while you're expunging, the change is still “in the wild”, and could propagate further.
If you've committed one or more changes after the change that you'd like to see disappear, your options are further reduced. Mercurial doesn't provide a way to “punch a hole” in history, leaving changesets intact.
Backing out a merge
Since merges are often complicated, it is not unheard of for a merge to be mangled badly, but committed erroneously. Mercurial provides an important safeguard against bad merges by refusing to commit unresolved files, but human ingenuity guarantees that it is still possible to mess a merge up and commit it.
Given a bad merge that has been committed, usually the
best way to approach it is to simply try to repair the damage
by hand. A complete disaster that cannot be easily fixed up
by hand ought to be very rare, but the hg backout command may help in
making the cleanup easier. It offers a --parent option, which lets
you specify which parent to revert to when backing out a
merge.
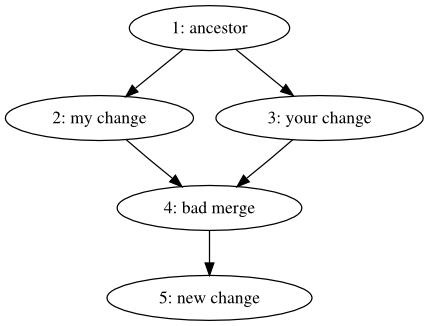
Suppose we have a revision graph like that in Figure 9.5, “A bad merge”. What we'd like is to redo the merge of revisions 2 and 3.
One way to do so would be as follows.
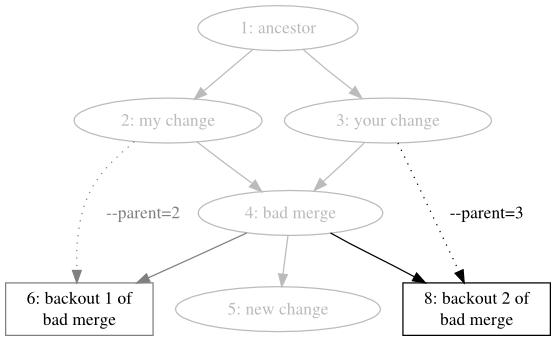
Call hg backout --rev=4 --parent=2. This tells hg backout to back out revision 4, which is the bad merge, and to when deciding which revision to prefer, to choose parent 2, one of the parents of the merge. The effect can be seen in Figure 9.6, “Backing out the merge, favoring one parent”.
Call hg backout --rev=4 --parent=3. This tells hg backout to back out revision 4 again, but this time to choose parent 3, the other parent of the merge. The result is visible in Figure 9.7, “Backing out the merge, favoring the other parent”, in which the repository now contains three heads.
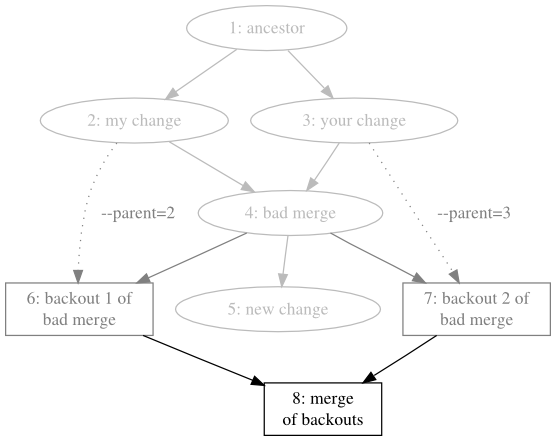
Redo the bad merge by merging the two backout heads, which reduces the number of heads in the repository to two, as can be seen in Figure 9.8, “Merging the backouts”.
Merge with the commit that was made after the bad merge, as shown in Figure 9.9, “Merging the backouts”.


Protect yourself from “escaped” changes
If you've committed some changes to your local repository and they've been pushed or pulled somewhere else, this isn't necessarily a disaster. You can protect yourself ahead of time against some classes of bad changeset. This is particularly easy if your team usually pulls changes from a central repository.
By configuring some hooks on that repository to validate incoming changesets (see chapter Chapter 10, Handling repository events with hooks), you can automatically prevent some kinds of bad changeset from being pushed to the central repository at all. With such a configuration in place, some kinds of bad changeset will naturally tend to “die out” because they can't propagate into the central repository. Better yet, this happens without any need for explicit intervention.
For instance, an incoming change hook that verifies that a changeset will actually compile can prevent people from inadvertently “breaking the build”.
What to do about sensitive changes that escape
Even a carefully run project can suffer an unfortunate event such as the committing and uncontrolled propagation of a file that contains important passwords.
If something like this happens to you, and the information that gets accidentally propagated is truly sensitive, your first step should be to mitigate the effect of the leak without trying to control the leak itself. If you are not 100% certain that you know exactly who could have seen the changes, you should immediately change passwords, cancel credit cards, or find some other way to make sure that the information that has leaked is no longer useful. In other words, assume that the change has propagated far and wide, and that there's nothing more you can do.
You might hope that there would be mechanisms you could use to either figure out who has seen a change or to erase the change permanently everywhere, but there are good reasons why these are not possible.
Mercurial does not provide an audit trail of who has pulled changes from a repository, because it is usually either impossible to record such information or trivial to spoof it. In a multi-user or networked environment, you should thus be extremely skeptical of yourself if you think that you have identified every place that a sensitive changeset has propagated to. Don't forget that people can and will send bundles by email, have their backup software save data offsite, carry repositories on USB sticks, and find other completely innocent ways to confound your attempts to track down every copy of a problematic change.
Mercurial also does not provide a way to make a file or changeset completely disappear from history, because there is no way to enforce its disappearance; someone could easily modify their copy of Mercurial to ignore such directives. In addition, even if Mercurial provided such a capability, someone who simply hadn't pulled a “make this file disappear” changeset wouldn't be affected by it, nor would web crawlers visiting at the wrong time, disk backups, or other mechanisms. Indeed, no distributed revision control system can make data reliably vanish. Providing the illusion of such control could easily give a false sense of security, and be worse than not providing it at all.
Finding the source of a bug
While it's all very well to be able to back out a changeset that introduced a bug, this requires that you know which changeset to back out. Mercurial provides an invaluable command, called hg bisect, that helps you to automate this process and accomplish it very efficiently.
The idea behind the hg bisect command is that a changeset has introduced some change of behavior that you can identify with a simple pass/fail test. You don't know which piece of code introduced the change, but you know how to test for the presence of the bug. The hg bisect command uses your test to direct its search for the changeset that introduced the code that caused the bug.
Here are a few scenarios to help you understand how you might apply this command.
The most recent version of your software has a bug that you remember wasn't present a few weeks ago, but you don't know when it was introduced. Here, your binary test checks for the presence of that bug.
You fixed a bug in a rush, and now it's time to close the entry in your team's bug database. The bug database requires a changeset ID when you close an entry, but you don't remember which changeset you fixed the bug in. Once again, your binary test checks for the presence of the bug.
Your software works correctly, but runs 15% slower than the last time you measured it. You want to know which changeset introduced the performance regression. In this case, your binary test measures the performance of your software, to see whether it's “fast” or “slow”.
The sizes of the components of your project that you ship exploded recently, and you suspect that something changed in the way you build your project.
From these examples, it should be clear that the hg bisect command is not useful only for finding the sources of bugs. You can use it to find any “emergent property” of a repository (anything that you can't find from a simple text search of the files in the tree) for which you can write a binary test.
We'll introduce a little bit of terminology here, just to make it clear which parts of the search process are your responsibility, and which are Mercurial's. A test is something that you run when hg bisect chooses a changeset. A probe is what hg bisect runs to tell whether a revision is good. Finally, we'll use the word “bisect”, as both a noun and a verb, to stand in for the phrase “search using the hg bisect command”.
One simple way to automate the searching process would be simply to probe every changeset. However, this scales poorly. If it took ten minutes to test a single changeset, and you had 10,000 changesets in your repository, the exhaustive approach would take on average 35 days to find the changeset that introduced a bug. Even if you knew that the bug was introduced by one of the last 500 changesets, and limited your search to those, you'd still be looking at over 40 hours to find the changeset that introduced your bug.
What the hg bisect command does is use its knowledge of the “shape” of your project's revision history to perform a search in time proportional to the logarithm of the number of changesets to check (the kind of search it performs is called a dichotomic search). With this approach, searching through 10,000 changesets will take less than three hours, even at ten minutes per test (the search will require about 14 tests). Limit your search to the last hundred changesets, and it will take only about an hour (roughly seven tests).
The hg bisect command is aware of the “branchy” nature of a Mercurial project's revision history, so it has no problems dealing with branches, merges, or multiple heads in a repository. It can prune entire branches of history with a single probe, which is how it operates so efficiently.
Using the hg bisect command
Here's an example of hg bisect in action.
![[Note]](figs/note.png)
Now let's create a repository, so that we can try out the hg bisect command in isolation.
$hg init mybug$cd mybug
We'll simulate a project that has a bug in it in a simple-minded way: create trivial changes in a loop, and nominate one specific change that will have the “bug”. This loop creates 35 changesets, each adding a single file to the repository. We'll represent our “bug” with a file that contains the text “i have a gub”.
$buggy_change=22$for (( i = 0; i < 35; i++ )); do>if [[ $i = $buggy_change ]]; then>echo 'i have a gub' > myfile$i>hg commit -q -A -m 'buggy changeset'>else>echo 'nothing to see here, move along' > myfile$i>hg commit -q -A -m 'normal changeset'>fi>done
The next thing that we'd like to do is figure out how to use the hg bisect command. We can use Mercurial's normal built-in help mechanism for this.
$hg help bisecthg bisect [-gbsr] [-c CMD] [REV] subdivision search of changesets This command helps to find changesets which introduce problems. To use, mark the earliest changeset you know exhibits the problem as bad, then mark the latest changeset which is free from the problem as good. Bisect will update your working directory to a revision for testing (unless the --noupdate option is specified). Once you have performed tests, mark the working directory as bad or good and bisect will either update to another candidate changeset or announce that it has found the bad revision. As a shortcut, you can also use the revision argument to mark a revision as good or bad without checking it out first. If you supply a command it will be used for automatic bisection. Its exit status will be used as flag to mark revision as bad or good. In case exit status is 0 the revision is marked as good, 125 - skipped, 127 (command not found) - bisection will be aborted; any other status bigger than 0 will mark revision as bad. options: -r --reset reset bisect state -g --good mark changeset good -b --bad mark changeset bad -s --skip skip testing changeset -c --command use command to check changeset state -U --noupdate do not update to target use "hg -v help bisect" to show global options
The hg bisect command works in steps. Each step proceeds as follows.
The process ends when hg bisect identifies a unique changeset that marks the point where your test transitioned from “succeeding” to “failing”.
To start the search, we must run the hg bisect --reset command.
$hg bisect --reset
In our case, the binary test we use is simple: we check to see if any file in the repository contains the string “i have a gub”. If it does, this changeset contains the change that “caused the bug”. By convention, a changeset that has the property we're searching for is “bad”, while one that doesn't is “good”.
Most of the time, the revision to which the working directory is synced (usually the tip) already exhibits the problem introduced by the buggy change, so we'll mark it as “bad”.
$hg bisect --bad
Our next task is to nominate a changeset that we know doesn't have the bug; the hg bisect command will “bracket” its search between the first pair of good and bad changesets. In our case, we know that revision 10 didn't have the bug. (I'll have more words about choosing the first “good” changeset later.)
$hg bisect --good 10Testing changeset 22:b8789808fc48 (24 changesets remaining, ~4 tests) 0 files updated, 0 files merged, 12 files removed, 0 files unresolved
Notice that this command printed some output.
We now run our test in the working directory. We use the grep command to see if our “bad” file is present in the working directory. If it is, this revision is bad; if not, this revision is good.
$if grep -q 'i have a gub' *>then>result=bad>else>result=good>fi$echo this revision is $resultthis revision is bad$hg bisect --$resultTesting changeset 16:e61fdddff53e (12 changesets remaining, ~3 tests) 0 files updated, 0 files merged, 6 files removed, 0 files unresolved
This test looks like a perfect candidate for automation, so let's turn it into a shell function.
$mytest() {>if grep -q 'i have a gub' *>then>result=bad>else>result=good>fi>echo this revision is $result>hg bisect --$result>}
We can now run an entire test step with a single command,
mytest.
$mytestthis revision is good Testing changeset 19:706df39b003b (6 changesets remaining, ~2 tests) 3 files updated, 0 files merged, 0 files removed, 0 files unresolved
A few more invocations of our canned test step command, and we're done.
$mytestthis revision is good Testing changeset 20:bf7ea9a054e6 (3 changesets remaining, ~1 tests) 1 files updated, 0 files merged, 0 files removed, 0 files unresolved$mytestthis revision is good Testing changeset 21:921391dd45c1 (2 changesets remaining, ~1 tests) 1 files updated, 0 files merged, 0 files removed, 0 files unresolved$mytestthis revision is good The first bad revision is: changeset: 22:b8789808fc48 user: Bryan O'Sullivan <[email protected]> date: Tue May 05 06:55:14 2009 +0000 summary: buggy changeset
Even though we had 40 changesets to search through, the hg bisect command let us find the changeset that introduced our “bug” with only five tests. Because the number of tests that the hg bisect command performs grows logarithmically with the number of changesets to search, the advantage that it has over the “brute force” search approach increases with every changeset you add.
Cleaning up after your search
When you're finished using the hg bisect command in a repository, you can use the hg bisect --reset command to drop the information it was using to drive your search. The command doesn't use much space, so it doesn't matter if you forget to run this command. However, hg bisect won't let you start a new search in that repository until you do a hg bisect --reset.
$hg bisect --reset
Tips for finding bugs effectively
Give consistent input
The hg bisect command requires that you correctly report the result of every test you perform. If you tell it that a test failed when it really succeeded, it might be able to detect the inconsistency. If it can identify an inconsistency in your reports, it will tell you that a particular changeset is both good and bad. However, it can't do this perfectly; it's about as likely to report the wrong changeset as the source of the bug.
Automate as much as possible
When I started using the hg bisect command, I tried a few times to run my tests by hand, on the command line. This is an approach that I, at least, am not suited to. After a few tries, I found that I was making enough mistakes that I was having to restart my searches several times before finally getting correct results.
My initial problems with driving the hg bisect command by hand occurred even with simple searches on small repositories; if the problem you're looking for is more subtle, or the number of tests that hg bisect must perform increases, the likelihood of operator error ruining the search is much higher. Once I started automating my tests, I had much better results.
The key to automated testing is twofold:
In my tutorial example above, the grep
command tests for the symptom, and the if
statement takes the result of this check and ensures that we
always feed the same input to the hg
bisect command. The mytest
function marries these together in a reproducible way, so that
every test is uniform and consistent.
Check your results
Because the output of a hg bisect search is only as good as the input you give it, don't take the changeset it reports as the absolute truth. A simple way to cross-check its report is to manually run your test at each of the following changesets:
Beware interference between bugs
It's possible that your search for one bug could be disrupted by the presence of another. For example, let's say your software crashes at revision 100, and worked correctly at revision 50. Unknown to you, someone else introduced a different crashing bug at revision 60, and fixed it at revision 80. This could distort your results in one of several ways.
It is possible that this other bug completely “masks” yours, which is to say that it occurs before your bug has a chance to manifest itself. If you can't avoid that other bug (for example, it prevents your project from building), and so can't tell whether your bug is present in a particular changeset, the hg bisect command cannot help you directly. Instead, you can mark a changeset as untested by running hg bisect --skip.
A different problem could arise if your test for a bug's presence is not specific enough. If you check for “my program crashes”, then both your crashing bug and an unrelated crashing bug that masks it will look like the same thing, and mislead hg bisect.
Another useful situation in which to use hg bisect --skip is if you can't test a revision because your project was in a broken and hence untestable state at that revision, perhaps because someone checked in a change that prevented the project from building.
Bracket your search lazily
Choosing the first “good” and “bad” changesets that will mark the end points of your search is often easy, but it bears a little discussion nevertheless. From the perspective of hg bisect, the “newest” changeset is conventionally “bad”, and the older changeset is “good”.
If you're having trouble remembering when a suitable “good” change was, so that you can tell hg bisect, you could do worse than testing changesets at random. Just remember to eliminate contenders that can't possibly exhibit the bug (perhaps because the feature with the bug isn't present yet) and those where another problem masks the bug (as I discussed above).
Even if you end up “early” by thousands of changesets or months of history, you will only add a handful of tests to the total number that hg bisect must perform, thanks to its logarithmic behavior.
 Want to stay up to date? Subscribe to the comment feed for
Want to stay up to date? Subscribe to the comment feed for